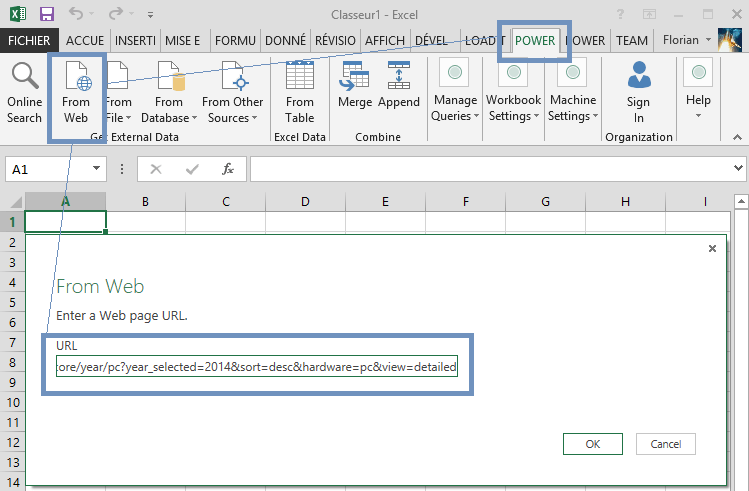
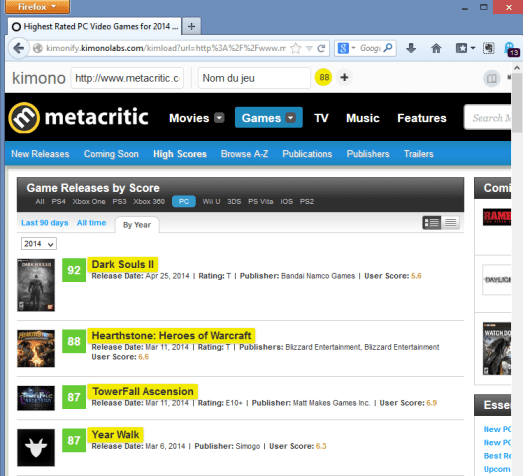
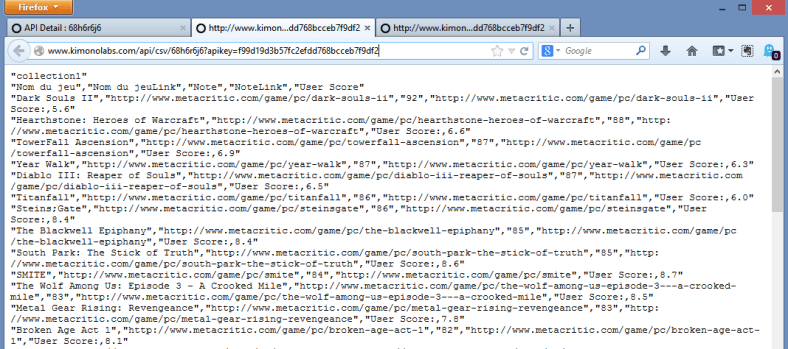
Lors de la keynote du PASS Summit 2014, le mois dernier à Seattle, nous avions eu droit à la présentation de la nouvelle organisation de l’équipe Data Platform de Microsoft, par son leadership flambant neuf:

Trois patrons pour trois lignes de produit, alignées comme indiqué sur ce schéma (désolé pour la qualité patate):
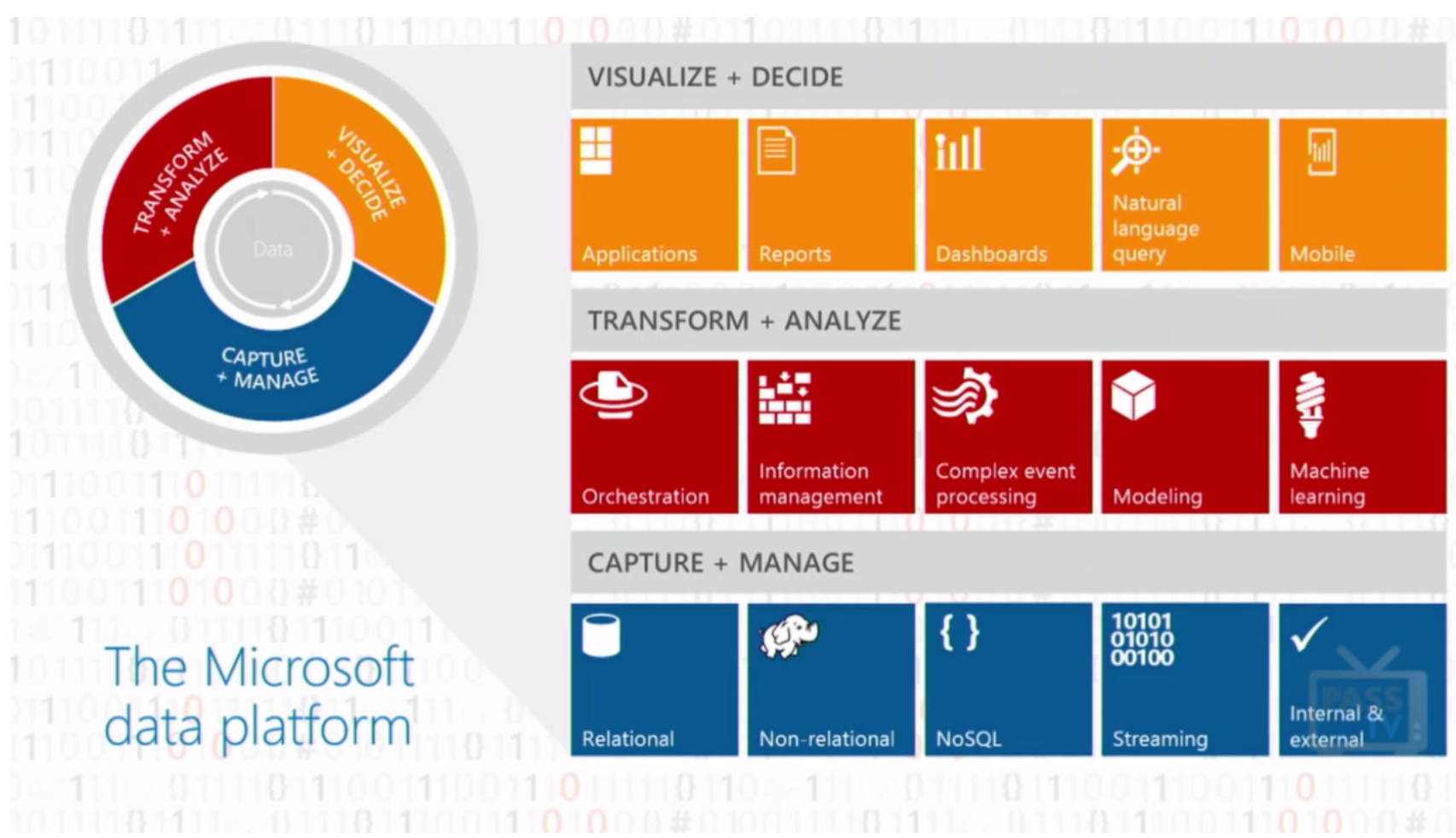
Si on repart du fond de la stack:
- Capture + Manage : T.K. « Ranga » Rengarajan, patron de Data Platform, Cloud & Entreprise. A comprendre : SQL Server, Azure SQL Database, Azure HDInsight, Azure DocumentDB, Azure Search and Analytics Platform System
- Transform + Analyze : Joseph Sirosh, patron de l’Information Management & Machine Learning. A comprendre : Tous les services Azure Data
- Visualize + Decide : James Phillips, patron de Power BI, tout du moins la partie sur O365 (dashboards, Q&A, Mobile…)
Là dessus je me fais les remarques suivantes:
- Ranga ancien SAP, Joseph ancien Amazon, James co-fondateur de Couchbase, les 3 ont moins de 2 ans d’ancienneté chez MS, ça sent l’air frais, c’est plutôt bon signe
- Ranga et Joseph sont CVP (haut gradés), James n’est « que » General Manager, bizarre cette différence de traitement…
- Vis à vis des périmètres de chacun:
- Pour Ranga on a une ligne claire de produits, énoncée dans sa fiche speaker, pas de doute possible
- Pour Joseph, il fallait être là en scéance mais ont été nommés : Azure Data Factory, Azure Stream Analytics et Azure Machine Learning. On en reparle plus bas.
- Pour James c’est moins clair. Power BI ça veut tout et rien dire, et si on s’en réfère au slide ci-dessus on note l’absence de la partie add-ins intégrée à Excel (soit à mon sens la plus importante), qui on le sait est retombée dans l’équipe Office. Bon il en parle quand même pendant la session, mais manifestement ça n’est pas dans son scope. Notons qu’il nous a parlé également de 2/3 autres trucs mignons qui arrivent et sont eux dans son scope : les Dashboards Power BI et l’amélioration du refresh on-premise/Power BI (genre SSAS et scheduling)
On en revient à Joseph, en reprennant le slide et en essayant de matcher les produits qu’on connaît en face:
- Orchestration -> Azure Data Factory
- Information Management -> ?
- Complex Event Processing -> Azure Stream Analytics
- Modeling -> ?
- Machine Learning -> Azure Machine Learning
Hum… Y’a des trous! Et si on observe le pattern, ça sent les services Azure managés, pour de l’Information Management et du Modeling! Wait, what?
Je ne sais pas vous, mais moi ça m’intrigue définitivement 😉