Je viens d’écrire une série d’article sur Azure Data Factory v2 que je ne voulais pas publier ici parce qu’elle est rédigée en anglais. Ceci n’étant pas une raison pour abandonner mes premières amours, voici la traduction du premier article de la série, centré sur l’architecture du projet.
Je ne pense pas traduire les autres: ils sont plus proches du code donc facile à comprendre même en traduction automatique. Désolé pour les fautes de frappes, je fais ce que je peux avec mon clavier qwerty 😉
Remarque: je suis employé de Microsoft au moment où je rédige cet article
Scenario
Périmètre
L’objectif de cet article est de partager les réflexions faites lors du design et de l’implémentation d’une pipeline d’ingestion de données, partie d’un projet plus large d’IoT basé sur des technologies Cloud.
Dans notre scenario, nous sommes un fournisseur de service gérant une plateforme Big Data centralisée. Les données que nous traitons viennent d’une multitude d’appareils similaires mais déployés chez plusieurs de nos clients (Company A, Company B…).
La chaîne de traitement va ingérer des fichiers publiés toutes les heures sur un serveur sFTP centralisé (un répertoire top niveau par client, cette étape est déjà implémentée). Elle va ensuite les décoder, les convertir (CSV a Parquet) et les déplacer dans le répertoire de staging de la plateforme Big Data.

Besoins techniques
- Des fichiers encodés (raw) sont publiés toutes les heures sur un serveur sFTP déployé dans un Virtual Network
- Le décodeur (decoder) est une application Windows qui convertit les fichiers en CSV
- La plateforme Big Data attend des fichiers Parquet en entrée
En plus de cela, les fichiers doivent être réorganisés d’une structure de répertoires hiérarchisées (Company\Year\Month\Device ID\xyz.csv), vers une structure à plat (Staging\year_month_company_device_xyz.csv). Ceci afin de faciliter l’ingestion par la plateforme Big Data.

Approche générale
Nous allons traiter les fichiers dans un batch qui tournera toutes les heures, en s’alignant sur leur rythme de génération.
Cela étant dit, par nature (IoT) nous manipulons ici des évènements. L’approche naturelle pour traiter des évènements est le temps réel (streaming). Pour moi la vraie solution, pérenne à long terme, serait de régénérer un flux d’évènements (stream) à partir des fichiers et d’utiliser des technologies d’ingestion en temps réel (Event Hub, Functions, Stream Analytics…) pour la suite des traitements. L’ingestion et la consommation de ces données en batch n’étant que la conséquence d’un détail d’implémentation existant.
Nous sommes missionné pour délivrer une solution en production dans un temps raisonnable, sans risque technique… nous avons donc décidé d’attendre que le besoin d’analyse en temps réel se manifeste pour passer sur du temps réel 😉
Nous aurons besoin d’un ETL avec des capacités Cloud pour orchestrer et exécuter le job, de moteurs de traitement (compute) pour déplacer et convertir les fichiers, et de solutions de stockage.
Éléments de la solution
Nous commencerons par choisir l’ETL puisque c’est la pièce centrale du puzzle. De cet ETL découlera la liste de moteurs de traitement disponibles, qui à leur tour indiqueront les solutions de stockage que nous pourrons employer.
ETL dans le Cloud
Nous utiliserons Azure Data Factory v2 (ADFv2) pour nos besoins d’ETL. Ce service nous permettra d’accéder à un large choix de solution de processing, que l’on pourra intégrer dans un unique flux d’orchestration (Control Flow).
ADFv2 offre:
- un connecteur natif sFTP
- une méthode pour accéder à des ressources résidant dans un Virtual Network (via self-hosted integration runtime, discuté ci-dessous)
- une conversion native de CSV à Parquet avec la Copy Activity
- A noter que c’est une approche temporaire, les Data Flows étant à préférer pour ce cas, mais toujours en preview à l’écriture de cet article
Une autre bonne raison de choisir ADFv2 est simplement que nous voulions tester le produit, alors qu’il se positionne comme la solution d’intégration en batch par défaut sur Azure.
Processing
ADFv2 peut utiliser deux types de moteurs de traitement:
Toutes les activités natives d’ADFv2 sont exécutées par un IR. Ce qui est bien c’est que chaque Factory vient avec un IR par défaut, managé par Microsoft (autoResolve IR). Ce qui est moins bien c’est que cet IR ne peut pas être configuré, y compris autour du networking. Il n’est donc pas utilisable dans le contexte d’un Virtual Network, dans notre cas il ne pourra pas toucher le serveur sFTP qui met à disposition nos fichiers. Afin de résoudre ce problème, nous allons déployer nous-même un « self-hosted » IR, sur une VM Windows que nous provisionnerons dans le Virtual Network, et l’enregistrer dans notre Factory.
Dans notre Factory, nous déclarerons nos services de stockage et les ferons utiliser l’IR qui correspond (via la propriété connectVia):
- soit self-hosted (pour accéder au Virtual Network)
- soit autoResolve (car c’est la seule capable de faire la conversion csv-parquet)
Enfin, à l’écriture de cet article, il n’existe pas d’activité native dans ADFv2 pour effacer des fichiers. Pour ce faire nous avons décidé d’utiliser une Logic App, en suivant cette stratégie, appliquée sur un File Store (voir Stockage ci-dessous). En alternative, nous avons essayé d’appeler directement la Delete REST API du File Store via une Web Activity, mais sommes rester bloqués sur l’authentification (pas de MSI disponible, contrairement aux Blobs). Nous avons également essayé la même approche avec une Function, mais là non plus sans succès (pas de support via le SDK, l’authentification via REST n’est pas évidente).
Stockage
Le décodeur est une application Windows qui écoute un répertoire d’entrée A, attrape les fichiers qui y apparaissent, les décode et les déplace vers un répertoire de sortie B.
Le transfert sFTP étant opéré par ADFv2, par un self hosted IR déployé localement, la manière la plus simple de positionner le décodeur est de l’installer sur une VM située dans le même Virtual Network. Nous monterons deux File Stores sur cette VM: pour l’entrée (A) et la sortie (B) des fichiers. Ces espaces de stockage seront à la fois accessibles par les outils Cloud, et vus comme des répertoires locaux par le décodeur.
Les fichiers seront mis à disposition de la plateforme Big Data dans un Blob Store, beaucoup plus pratique à utiliser dans ce contexte.
Solution
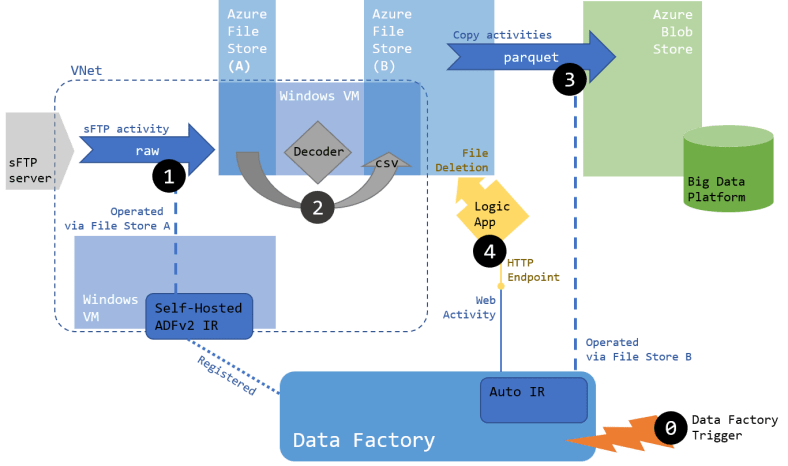
Architecture

Vis à vis de la planification:
- L’étape 1 (copie du serveur sFTP vers A) doit être déclenchée par un trigger externe (0), planifié pour s’exécuter toutes les heures
- L’étape 2 (de A vers B) est rendu par le décodeur, déclenché automatiquement sur écoute du répertoire A (quand un nouveau fichier apparaît)
- Ce qui veut dire qu’idéalement les étapes 3 et 4 (3: copie et conversion des fichiers de B vers le Blob, 4: Logic App qui efface les fichiers) devraient elles aussi être déclenchées sur écoute, mais du répertoire B. Malheureusement ce n’est pas une fonctionnalité existante des File Stores (via ADFv2, Logic App ou Function). Une solution de contournement satisfaisante dans notre cas sera de déclencher 3 et 4 via un trigger planifié pour s’exécuter toutes les 15 minutes
Pour le stockage:

Coûts
A partir du volume de donnée attendu et de la liste des services employés, nous pouvons utiliser la calculatrice des prix d’Azure et obtenir une première estimation de la consommation mensuelle pour notre solution (en USD):
- Data Factory : 250$
- Logic Apps : 70$
- Storage : 140$
- VMs : 600$
- VNet : 2$
- Total : 1062$ (USD, par mois, 24/7 toutes les 15 minutes)
Il est important de voir ce chiffre comme une hypothèse qui doit être testée et validée. Entre les métriques obscures de la calculatrice et les larges possibilités d’optimisation de coût, il faut savoir investir du temps pour maîtriser sa consommation à long terme.
Alternatives
Il existe un nombre d’alternatives valables, de la solution poids lourd (HDInsight, Databricks…) au serverless (Function, Logic Apps…).
La suite
En anglais:


















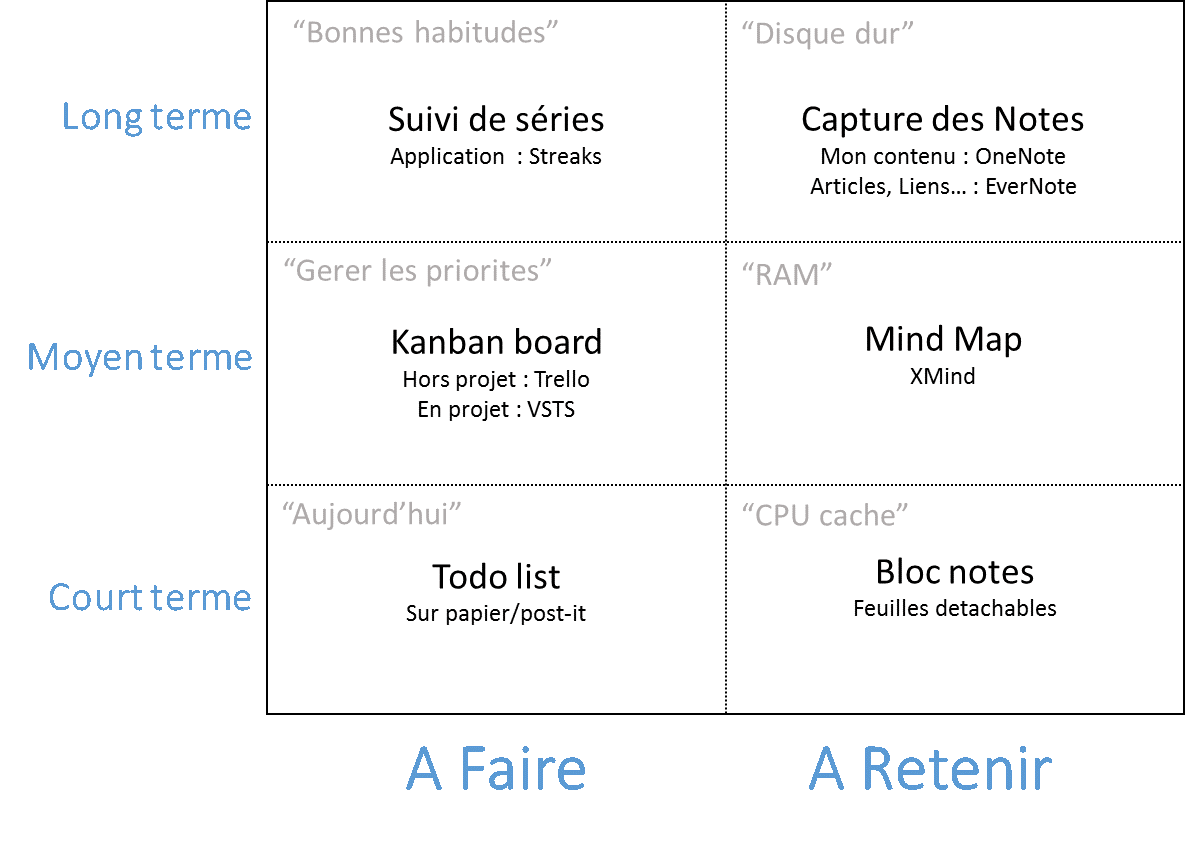 L’objectif c’est d’alléger au maximum le nombre de choses à garder en tête, la liste de courses, l’email à envoyer au client, se souvenir de préparer la réunion de la semaine prochaine… pour alléger le stress et concentrer son énergie cognitive sur des taches productives.
L’objectif c’est d’alléger au maximum le nombre de choses à garder en tête, la liste de courses, l’email à envoyer au client, se souvenir de préparer la réunion de la semaine prochaine… pour alléger le stress et concentrer son énergie cognitive sur des taches productives.