Comme vous le savez peut-être, cette année encore je co-animerai la session Modélisation Dimensionnelle aux Journées SQL Server 2012, les 10 et 11 décembre sur Paris, avec mon camarade Charles-Henri. Cette année on passe level 300 (ça commence à causer plus sérieusement) et franchement je pense qu’on va passer un bon moment 🙂
En attendant le jour J, je voulais vous parler d’une technique qui ne sera pas présentée lors de la session : celle de la table de faits universelle. Rencontrée chez un client dernièrement, c’est une modélisation qu’on peut aussi appeler la table de faits unique. Une table de faits pour les gouverner toutes. Une table de faits pour les trouver. Une table de faits pour les amener toutes et dans les ténèbres les lier… Hum… Je divague…

Je te vois faire n’importe quoi!
Si ça avait été fait par un stagiaire, ou un client qui s’essayait au décisionnel en dilettante, je trouverais ça mignon. Sincèrement. J’applaudirais pour l’effort et on prendrait une demi-journée ensemble pour causer modélisation. Mais là c’est réalisé par une équipe de consultants spécialisés dans le décisionnel.
Et c’est facturé. Moins mignon.
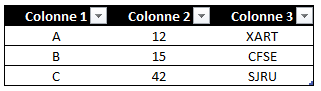
Alors voyons à quoi ça ressemble:

Dans cette même table de faits, qui s’appelle juste « Fait » (c’est plus simple) on retrouve :
- Les ventes quotidiennes
- L’inventaire hebdomadaire
- Les budgets trimestriels des magasins
- Les objectifs trimestriels des commerciaux
C’est quand même bien fait ! On a tout sous les yeux d’un seul coup. Pas besoin de jointures, les requêtes SQL sont simplissimes. Alors que reprocher à cette modélisation ?
Déjà, je vous avoue qu’en 6 ans de missions en décisionnel, je n’ai jamais vu ça. J’en ai même parlé lors d’un afterworks du GUSS, auquel étaient présents des consultants d’à peu près tous les pure-players en décisionnel Microsoft, et personne n’en avait entendu parler non plus.
Mais vous me connaissez, je n’allais pas me limiter à ça. Regardons donc ce qu’en dit la littérature :
- Wikipedia – Fact Table : “In data warehousing, a fact table consists of the measurements, metrics or facts of a business process.” Une table de faits pour un processus métier donc, les ventes ou l’inventaire ou les budgets… mais un seul. J’avoue, en effet, ils auraient pu insister et mettre: “ a SINGLE business process”. Mais à mon avis personne ne se doutait qu’on verrait arriver la table de faits unique.
- Wikipedia – Base de données relationnelle : « Dans une base de données relationnelle chaque enregistrement d’une table contient un groupe d’informations relatives à un sujet (…) ». Même commentaire, et là on parle de toute la technologie de la base de données relationnelle, plus seulement du décisionnel.
- Ralph Kimball, l’inventeur du schéma en étoile, indique lui que chaque table de faits représente un processus métier, que chacune de ces tables est reliée à des dimensions, les mêmes dimensions pour tout le monde (alors dites conformées), et que toute la valeur de la modélisation en étoile vient justement de là. Parce qu’entre nous, quitte à faire une table de fait unique, autant pas s’embêter à faire des tables de dimensions hein… Et là le lien je le fais par vers un article spécifique, mais vers le bouquin de Kimball, parce qu’à un moment il va falloir le lire ce livre si vous vous dites consultant ou développeur décisionnel.
- Bill Inmon, l’inventeur du schéma en flocon, indique la même chose. En effet les différences entre les deux modèles se situent au niveau de la structure des dimensions et du processus de génération du modèle, pas des tables de faits.
- Et quid de Datavault ? La troisième modélisation très contestée du décisionnel ? Là c’est pire puisqu’on normalise complètement et qu’on conserve le format source original (une table pour les clients, une table pour les magasins, une table de relation entre les 2, etc, etc). Pas de table unique en vue.
Pas de chance, la littérature ne fait donc aucune mention de cette technique, et c’est même plutôt l’inverse qui est recommandé : créer une table de faits par processus métier. Soit dans notre cas, 4 tables : ventes, inventaires, budgets et objectifs.
Je précise au passage que dans ces sources, il ne faut pas interpréter la phrase « la table de faits est au centre du schéma en étoile » comme une indication qu’il n’y en ait qu’une seule. En effet un datawarehouse ce n’est pas un mais plusieurs schémas en étoile, plusieurs datamarts, autant qu’il y a de processus métier. Et en théorie l’ensemble de ces étoiles s’appelle une constellation, mais ça devient trop poétique donc on emploie rarement le terme.
D’une manière plus pratique, si on abandonne la littérature et qu’on s’interroge sur les mérites d’une telle modélisation, on peut se faire les réflexions suivantes :
- Performances
- A priori elles ne seront navrantes. En effet pour aller chercher un élément particulier de la table (les budgets), le moteur doit parcourir toutes les lignes de la table (les ventes, les inventaires…). C’est largement inefficace.
- L’index le plus rapide de tous est l’index cluster (celui qui dicte comment les données sont écrites sur le disque). Comme vous le savez, on ne peut en définir qu’un seul par table (par définition). Tout mettre dans la même table c’est donc se priver d’un des meilleurs outils d’optimisation de la base de données. A la place d’en avoir un par processus métier, il n’y en aura qu’un seul, qui en plus ne sera pas très bon. Car évidemment, l’index s’optimise différemment en fonction du sujet. On indexe les ventes (par jour/magasin/produit) différemment qu’on indexe les objectifs (par trimestre/commerciaux). Et croisez les doigts pour que l’unicité des lignes des 4 processus métiers tiennent en moins de 16 colonnes.
- Même remarque pour le partitionnement.
- Confort d’utilisation / Qualité du requêtage
- Si on s’économise les jointures en SQL, j’ai peur de ce à quoi vont ressembler les clauses WHERE. Et on n’a pas intérêt à se tromper sur ces filtres, sans quoi on va additionner des choux et des carottes (des quantités de ventes et des quantités d’inventaires). Le risque métier est important avec cette approche, il est inexistant avec la modélisation classique.
- Et là où les jointures reviendront en force, c’est si on veut obtenir un état avec par exemple du budget et du facturé. Il faudra en effet faire une auto jointure (en FULL OUTER JOIN) de la table unique sur elle-même. Ce sera douloureux en écriture de requête et en performance.
- Enfin, on l’a bien compris, impossible d’exposer ce modèle directement à un utilisateur. Il faudra définir un modèle de métadonnées devant chaque outil de reporting (Excel, Tableau, SSAS, SSRS…). Attention au coût de développement masqué.
- Maintenabilité / Evolutivité
- J’ai peur que l’ajout d’un nouveau processus métier (comme il est prévu dans le lot 2 j’imagine ?) ne se traduise par l’ajout de nouvelles colonnes dans cette table. Dans ce cas il faudra changer toutes les requêtes déjà développées (clauses WHERE, agrégations), toutes les métadonnées, et toutes les optimisations déjà réalisées. En somme il faudra tout refaire. A chaque évolution.
- Enfin, si on s’enferme dans cette architecture, impossible de trouver un prestataire digne de ce nom qui assurera la TMA ou les évolutions sans d’abord tout refondre.
Bon et bien on le voit, si c’est une nouvelle théorie, c’est l’équivalent de remplacer les groupes sanguins par les signes du zodiaque pour déterminer la compatibilité dans les transfusions sanguines. De temps en temps ça va marcher, certes, mais sur le long terme…
Et sinon, comment modéliser ça de manière satisfaisante ?
En identifiant les dimensions utilisées pour chaque processus métier, leur grain, et en construisant les tables de fait en fonction (c’est dans le livre, ou dans le webcast) :
")
PS : Les périodes temporelles diverses (semaines, trimestres) sont gérées directement dans la dimension temps.
Là on dispose d’une constellation composée de 4 étoiles, qui utilise des dimensions conformées (partagées), qui répond aux problématiques de performance, de confort d’utilisation et de maintenabilité. Si on souhaite intégrer un nouveau processus métier, on ajoute une nouvelle table de faits, sans avoir à modifier l’existant. Chaque processus peut évoluer indépendamment des autres. Chaque amélioration d’une dimension profite à toutes les analyses.
De tout ça on en reparle lundi 10 décembre, aux Journées SQL Server 2012. Inscrivez-vous 😉










")
