Je pique exceptionnellement le flambeau à François pour moi aussi vous causer MDX. Évidemment ça ne sera pas aussi pointu (voir piquant) que lui, mais pour une fois j’ai quelque chose à dire sur ce sujet…
A la base mon besoin était assez simple : créer un graph dans SSRS avec une date de départ et une date de fin fixées par des attributs de dimension de SSAS.
Typiquement : j’ai une dimension projet, dans cette dimension j’ai un attribut date de départ théorique (DDT), et un attribut date de fin théorique (DFT). Je veux que peu importent mes faits, mon graph couvre cette période théorique :

A mon sens la grande méthode pour faire ça c’est de créer un set de dates allant de la DTD à la DTF. Ce set doit évidemment être composé d’éléments de la dimension Temps utilisée dans le groupe de mesure concerné, il va donc falloir passer des attributs de la dimension projet ([Projet].[DDT].&[…] et [Projet].[DDF].&[…]) à la dimension temps ([Temps].[Date].&[…]).
Le MDX étant un langage particulièrement efficace en termes de manipulation de chaînes de caractères (hur hur), ça va être un bonheur… Trêve de sarcasme, on peut utiliser quelques fonctions VBA en MDX qui vont ici nous sauver la mise (à adapter en fonction des formats de vos dates):

Ce n’est pas ultra élégant, mais ça marche… pas !
Le message d’erreur : La fonction Axis1 attend une expression d’ensemble de tuples pour l’argument . Une expression de chaîne ou numérique a été utilisée.
Notez que la manipulation de projection des dates sur la dimension Temps marche, elle. C’est autre chose qui coince.
Le problème c’est qu’au moment où TimeSet est évalué, on n’a pas de CURRENTMEMBER sur la dimension Projet. En effet, en même temps (ON 1) qu’on essaye de résoudre TimeSet, on parcourt la dimension Projet, le CURRENTMEMBER n’est donc pas figé. On reçoit donc ALL dans le MEMBER_VALUE, que le STRTOMEMBER n’arrive pas à mapper correctement sur la dimension Temps. C’est le drame.
Tout ça parce que comme en SQL, en MDX le moteur interprète la requête dans un certain ordre. En faisant un gros raccourci, ici il commence par le FROM, puis le WHERE (slicer), puis les axes en itérant sur le 1 pour résoudre le 0. Dans une étape, tous les éléments sont interprétés en même temps : ça coince effectivement sur le TimeSet.
J’ai du mal à trouver des articles intéressants sur ce sujet, n’hésitez pas à soumettre les vôtres.
Pour comprendre le problème, on peut repartir d’une requête MDX plus simple, et basée sur AdventureWorks (je ne caste plus ma Start Date sur la dimension temps, je veux juste la faire apparaître en ON 1 comme dans mon cas réel):
WITH
MEMBER Test1 AS [Product].[Start Date].CURRENTMEMBER.MEMBER_UNIQUE_NAME
SELECT
[Measures].[Order Count] ON 0,
STRTOMEMBER(Test1)
*
[Product].[Product].[Product].MEMBERS ON 1
FROM [Adventure Works]
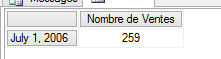
Le résultat, ma date est remplacée par ALL (« Tous les Produits ») dans le STRTOMEMBER(Test1) :

Si maintenant je filtre mon produit en slicer (typiquement l’endroit où on mettra le paramètre du rapport pour SSRS), la requête devient valide :
WITH
MEMBER Test1 AS [Product].[Start Date].CURRENTMEMBER.MEMBER_UNIQUE_NAME
SELECT
[Measures].[Order Count] ON 0,
STRTOMEMBER(Test1) ON 1
— *
— [Product].[Product].[Product].MEMBERS ON 1
FROM [Adventure Works]
WHERE [Product].[Product].&[447]
Ici il existe un CURRENTMEMBER au moment où on évalue Test1, tout roule. La solution est trouvée pour mon rapport, à moi de placer mon STRTOMEMBER(@Parameter) dans le WHERE.
Mais oui mais vous voulez itérer en même temps sur le TimeSet/Test1 et les projets/produits ? Il va falloir siouxer et passer l’attribut dans une mesure.
WITH
MEMBER [Measures].Test1 AS [Product].[Start Date].CURRENTMEMBER.MEMBER_UNIQUE_NAME
SELECT
{[Measures].[Order Count],Test1} ON 0,
[Product].[Product].[Product].MEMBERS ON 1
FROM [Adventure Works]
Ce qui donne:

Si ça marche pour le cas simple, on perd le cas d’application premier avec le TimeSet. Je n’ai malheureusement pas de solution à l’instant T. Si ça me vient je compléterai.
On a donc vu deux choses : comment passer d’un attribut d’une dimension à une autre grâce aux commandes VBA, et l’ordre d’exécution d’une requête MDX et comment il peut casser vos jolies sets et membres calculés. J’aimerai en rajouter une troisième, la propagation des contraintes sur les attributs dans les dimensions. François en avait parlé aux derniers JSS, j’en remets rapidement une couche ici.
Si quand vous passez votre filtre en WHERE vous utilisez la clef de la dimension, ça marche :
WITH
MEMBER Test1 AS [Product].[Start Date].CURRENTMEMBER.MEMBER_UNIQUE_NAME
SELECT
[Measures].[Order Count] ON 0,
STRTOMEMBER(Test1) ON 1
FROM [Adventure Works]
WHERE [Product].[Product].&[447]

Par contre si vous utilisez un attribut de plus haut niveau, ça ne marchera pas :
WITH
MEMBER Test1 AS [Product].[Start Date].CURRENTMEMBER.MEMBER_UNIQUE_NAME
SELECT
[Measures].[Order Count] ON 0,
STRTOMEMBER(Test1) ON 1
FROM [Adventure Works]
WHERE [Product].[Model Name].&[Cable Lock]

En effet, si on affiche les relations entre les attributs de la dimension (via SSDT BI), on verra que le Model Name ne contraint pas la Start Date, puisque si les contraintes peuvent remonter l’arbre (Model Name vers Product), elles ne le redescendent pas à partir de là (Product vers Start Date).
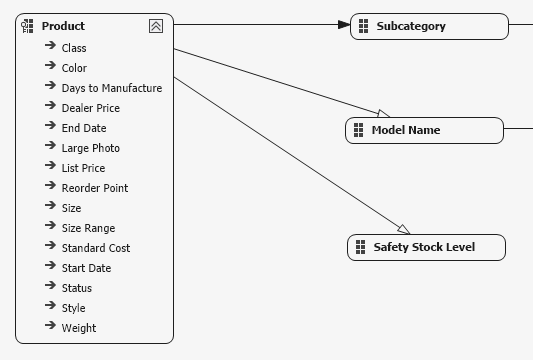 A vous d’utiliser les bons attributs, et de bien construire vos cubes, pour que les requêtes fonctionnent bien.
A vous d’utiliser les bons attributs, et de bien construire vos cubes, pour que les requêtes fonctionnent bien.
Utilisation du VBA, ordre de résolution des requêtes, propagation des contraintes sur les attributs… Pfiou, c’était du lourd tout ça ! Heureusement que le DAX arrive pour simplifier tout ça (hur hur).
Spéciale dédicace à Jordan Mootoosamy, qui a bien souffert avec moi sur cette requête 😉









