Un cas d’usage qui pouvait être reproché à Excel, et à Power Pivot également, c’était l’impossibilité de prendre 2 ou plus sources de données identiques et de les mettre bout à bout (en mode UNION pour les SQLeux). Typiquement : j’ai un fichier CSV par mois dans un répertoire, et j’aimerais tous les mettre dans le même tableau Excel pour travailler dessus. Jusqu’alors, la seule solution c’était les copiés/collés successifs à la main, avec tous les risques que ça comporte.
Heureusement Power Query (anciennement Data Explorer) vient à la rescousse ! C’est quoi ? C’est un add-in Excel gratuit, édité par Microsoft, qui sert de mini-ETL à Excel. Sincèrement, c’est peut-être l’outil de BI Self-Service qui enflamme le plus les consultants décisionnel Microsoft en ce moment, alors allez l’installer!
Le mieux pour vous convaincre étant sans doute de passer à la pratique, voici comment employer la chose :
Scénario 1 : 3 tableaux dans le même fichier Excel
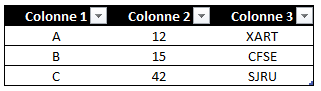
- Pour l’exemple j’ai créé 3 tableaux dans Excel 2013, dans la même feuille ou pas, ça ne change rien, qui contiennent des données à la structure identique:

- Le but : créer une « Query », une requête dans Power Query, sur chacune des tables, pour ensuite les associer en un seul résultat
- Etape 1 (à répéter 3 fois, une fois par tableau) : a. Je clique dans un tableau (si ce n’est pas fait, n’oubliez pas de « Mettre sous Forme de Tableau » vos données), b. Je vais dans l’onglet Power Query, c. Je créé une Query depuis un Tableau (From Table). Notez que si l’onglet Power Query n’apparait pas, le mieux est de valider qu’il est bien activé (Fichier > Options > Compléments > Gérer : Compléments COM : « Microsoft Power Query for Excel » doit être coché)

- En bleu : l’interface de transformation de données de Power Query, ici on a besoin de rien, donc on valide (Done):
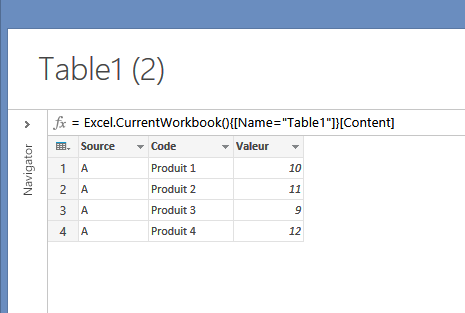
- La Query est créée, elle correspond à un tableau dans un nouvel onglet Excel:

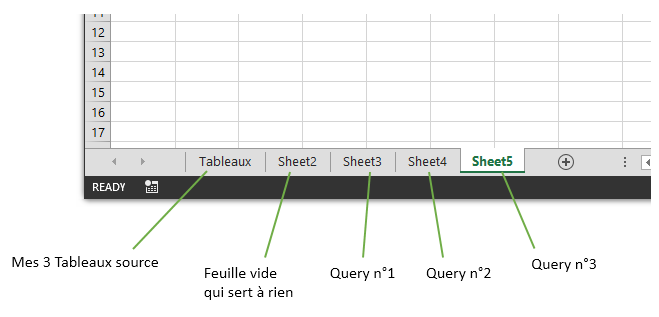
- On répète l’opération 3 fois, une fois par tableau pour obtenir les onglets suivants (oui mon Excel est en anglais, Sheet ou Feuille c’est pareil ;)) :
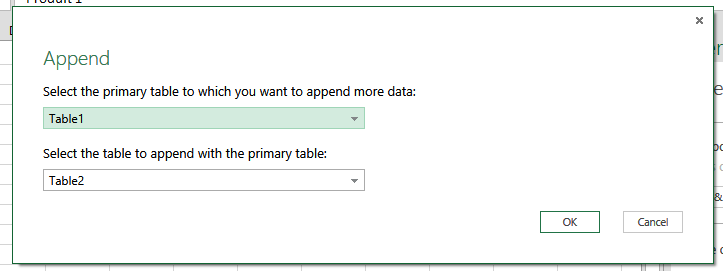
- Etape 2 : a. On va dans l’onglet Power Query, et b. on choisit « Append »

- Dans l’interface, je choisis 2 Queries, l’ordre n’importe pas ici. Vous noterez que les noms affichés sont les noms des Queries, qui par hasard correspondent ici aux noms des Tableaux. Si vous avez renommé vos Queries, vous retrouverez les nouveaux noms ici:
- Encore une fois, on passe par l’interface de transformation des données de Power Query, encore une fois ici on ne change rien, on valide (Done) :

- Et hop, je me retrouve avec une nouvelle Query qui est la mise bout à bout des 2 premières tables :
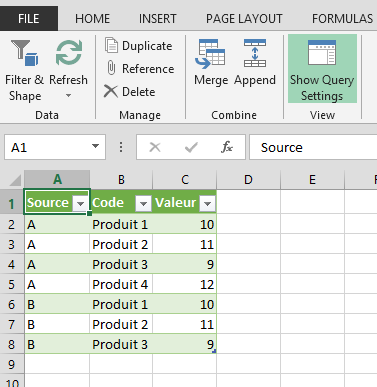
- Je répète l’opération, cette fois on prenant dans l’Append le résultat de mon premier Append (Append 1) et le tableau que je n’avais pas pris la première fois :

- Je valide dans l’éditeur et hop, me voilà avec la table complète !
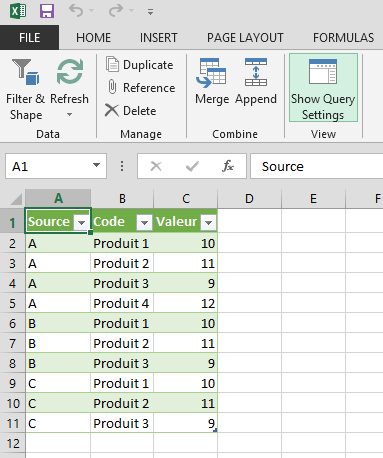
- Chouette non? Alors on peut se dire que c’était beaucoup d’étapes, alors que 3 copiés/collers suffisaient à faire la même chose. Certes. Mais l’avantage énorme des Queries, c’est qu’elles se mettent à jour (cliquer pour zoomer) :

- C’est quand même bien fait non ? 🙂
Scénario 1 – Avancé : Optimisation sur 3 tableaux dans le même fichier Excel
Alors ok, c’est mignon, mais avec la manipulation précédente on se retrouve quand même avec 5 feuilles, et si on ajoute d’autres sources ça va rapidement faire beaucoup trop (2n-1 feuilles avec n sources). Évidemment on peut faire bien mieux, mais il va falloir remonter les manches 😉
- D’abord il va falloir activer le mode avancé
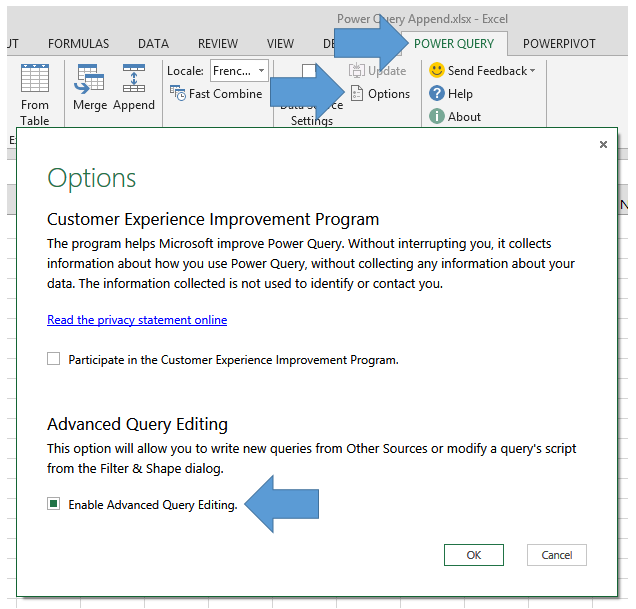
- Et tant qu’on y est, activez le Fast Combine, ça vous évitera des soucis plus tard :
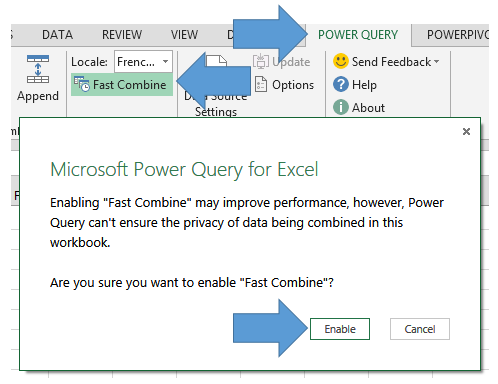
- Désormais, vous allez pouvoir directement éditer les formules que Power Query utilise pour transformer les données. On retourne donc dans l’interface de transformation des données de Power Query en utilisant une de ces 2 méthodes (ab,ab’c’), ou en créant une nouvelle Query :
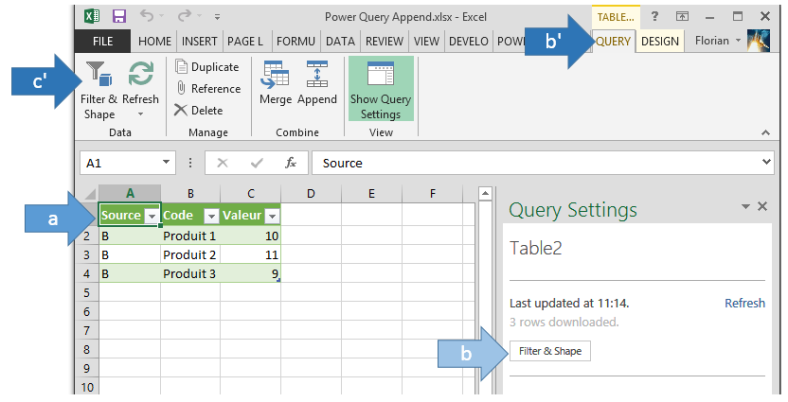
- Et dans cette interface, si vous êtes bien passé en mode avancé (voir plus haut), vous devez avoir un petit parchemin à cliquer :
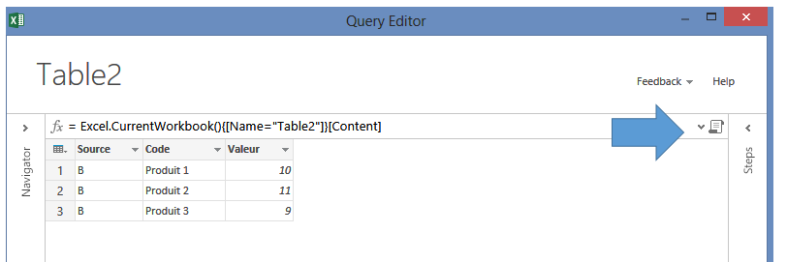
- Qui amène à l’interface de saisie des formules :
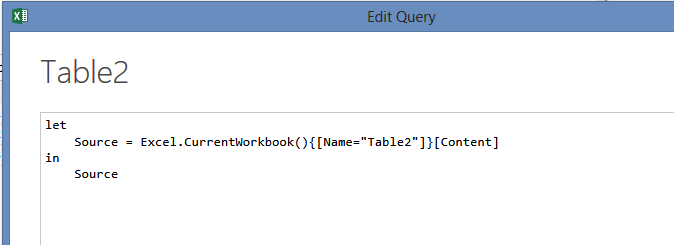
- Je vous laisse avec le guide de référence pour voir tout ce qui est possible de faire, perso j’ai la même démarche que dans cet article, je fais toutes les étapes unitairement, et j’essaye d’optimiser ensuite à la main. Dans notre cas :

- En version copiable, à adapter en fonction des noms de vos tableaux (Table1/Table2/Table3) :
let
Source1 = Excel.CurrentWorkbook(){[Name="Table1"]}[Content],
Source2 = Excel.CurrentWorkbook(){[Name="Table2"]}[Content],
Source3 = Excel.CurrentWorkbook(){[Name="Table3"]}[Content],
Source = Table.Combine({Source1,Source2,Source3})
in
Source
Avec cette formule on fait tout en une seule Query, donc un seul onglet, peu importe le nombre de source. Pas mal non ? 🙂
Scénario 2 : 3 fichiers Excel distincts, toujours avec le même format de données
- Alors de la même manière, on peut faire les fichiers Excel. Je vous donne directement le script, à vous de jouer en manuel pour bien comprendre !
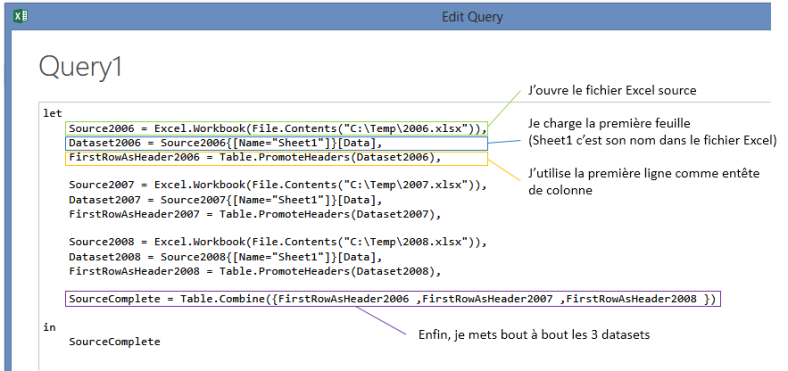
let
Source2006 = Excel.Workbook(File.Contents("C:\Temp\2006.xlsx")),
Dataset2006 = Source2006{[Name="Sheet1"]}[Data],
FirstRowAsHeader2006 = Table.PromoteHeaders(Dataset2006),
Source2007 = Excel.Workbook(File.Contents("C:\Temp\2007.xlsx")),
Dataset2007 = Source2007{[Name="Sheet1"]}[Data],
FirstRowAsHeader2007 = Table.PromoteHeaders(Dataset2007),
Source2008 = Excel.Workbook(File.Contents("C:\Temp\2008.xlsx")),
Dataset2008 = Source2008{[Name="Sheet1"]}[Data],
FirstRowAsHeader2008 = Table.PromoteHeaders(Dataset2008),
SourceComplete = Table.Combine({FirstRowAsHeader2006 ,FirstRowAsHeader2007 ,FirstRowAsHeader2008 })
in
SourceComplete
Scénario 3 : 3 fichiers CSV, toujours avec le même format de données
- Je vous donne directement le script :

let
Source2006 = Csv.Document(File.Contents("C:\Temp\2006.csv")),
FirstRowAsHeader2006 = Table.PromoteHeaders(Source2006),
Source2007 = Csv.Document(File.Contents("C:\Temp\2007.csv")),
FirstRowAsHeader2007 = Table.PromoteHeaders(Source2007),
Source2008 = Csv.Document(File.Contents("C:\Temp\2008.csv")),
FirstRowAsHeader2008 = Table.PromoteHeaders(Source2008),
SourceComplete = Table.Combine({FirstRowAsHeader2006 ,FirstRowAsHeader2007 ,FirstRowAsHeader2008 }),
ChangedType = Table.TransformColumnTypes(SourceComplete ,{{"Region", type text}, {"Categorie", type text}, {"Annee", type number}, {"Valeur", type text}})
in
ChangedType
- Une petite remarque en passant : attention avec les CSV, pour le moment l’interface de Power Query ne permet pas de gérer les séparateurs différents de la virgule, ni nos encodages européens facilement. Pour se faire, il faut modifier sa formule source comme suit:
Csv.Document(File.Contents("C:\Users\Florian\Desktop\2006.csv"), null, ";" , null, 1252)
Avec : votre séparateur, et votre encodage (par défaut 1252 sur Windows, voir le PDF de référence pour les autres – recherchez TextEncoding).
Et après ?
Soit on utilise directement le tableau résultat des Queries Append dans un tableau croisé dynamique, soit on l’ajoute au Data Model et c’est parti pour Power Pivot !
Amusez-vous bien, et n’hésitez pas à venir partager vos trouvailles 😉