Un peu de contexte: j’ai assisté à quelques sessions du dernier 24h of PASS, 12 sessions d’1h en webcast, de très grande qualité, organisées par le PASS, suivi de 12h de rediffusion. Les enregistrements sont déjà disponibles en streaming. Je vous livre ici un petit compte rendu de ce que j’ai appris.
Sessions: Big Data on the Microsoft Platform (Vidéo)
Speaker: Andrew J. Brust – CEO / Consultant / Blogger (Linkedin – Blog – Twitter)
A retenir:
- Big Data c’est, entre autres :
- Du volume, quand ça commence à coincer sur nos plateformes habituelles (100+TB)
- Du temps réel, quand on est obligé de streamer les données (finance de marché, capteurs industriels, média social, des interactions plutôt que des transactions…)
- Des données non structurées ou semi structurées, pour lesquelles nos outils doivent être trop adaptés pour que ce soit rentable / il faille utiliser de nouveaux outils
- Hadoop c’est : un framework java, version open source du système de gestion des gros volumes de données de Google. C’est un outil Big Data parmi d’autres. Deux composants principaux :
- HDFS : qui permet de stocker les données de façon distribuée, sur un cluster (un assemblage de serveurs composés de hardware standard).
- MapReduce : qui permet de manipuler ces données
- MapReduce c’est : du code Java qui réalise les opérations de manipulation des données hébergées sur HDFS :
- Langage : à la base du Java, on peut désormais « streamer » du C# (cf HDInsight plus bas), ou plus simplement passer par du JavaScript (par exemple sur Azure)
- Opérations : un schéma vaut une longue explication
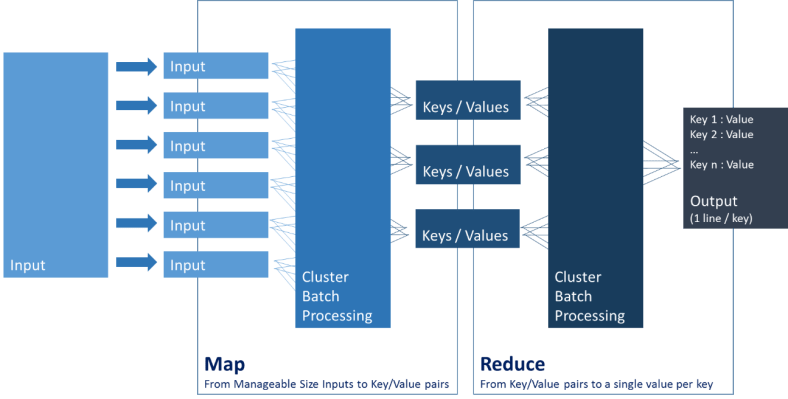
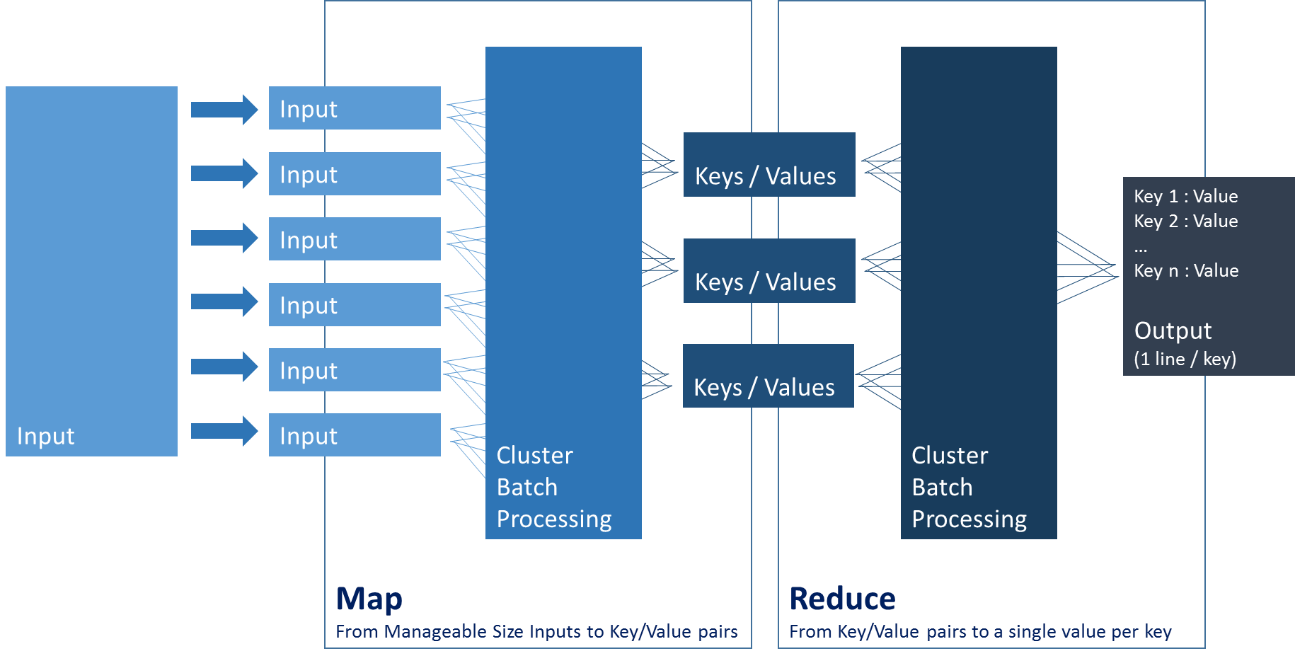
- Une implémentation de Hadoop c’est :
- Du HDFS sur un cluster pour stocker les données. On peut les manipuler directement, manuellement, avec des batchs MapReduce.
- HBase : (optionnel) une base NoSQL dont les tables sont des fichiers HDFS.
- Hive : une surcouche SQL (hiveQL) pour requêter sur les données (à travers HBase ou pas), qui génère du MapReduce. Il existe un connecteur ODBC vers Hive, pour le moment en beta dans HDInsight.
- Pig : une surcouche de transformation de données dans un langage spécifique (Pig Latin), qui génère du MapReduce.
- Mahout : une surcouche de datamining et machine learning, qui génère du MapReduce.
- Flume : une surcouche pour intégrer des log files, qui génère du MapReduce.
- Sqoop : une surcouche pour intégrer des données depuis des bases, qui génère du MapReduce.
- …
- HDInsight c’est : Hadoop sur Windows dans le cloud (Azure) ou en local avec :
- le stockage distribué des fichiers,
- une implémentation MapReduce,
- un SDK .NET pour les développeurs (des outils permettant d’attaquer le tout depuis Visual Studio).
Mon avis: Excellente présentation. Il a dressé une image claire et sans fausses promesses de l’écosystème Big Data Microsoft. Vraiment top. Par ailleurs si vous voulez creuser le sujet, je vous conseille cette série d’article en français que mon camarade Romain Casteres a co-écrit.

Un commentaire sur « 24h of PASS: Andrew Brust – Big Data sur la plateforme Microsoft SQL Server »